©️ arts & crafts All rights reserved.
UiPath公式アクティビティでOCRを使用する
目次

UiPathで使用できるOCRアクティビティ
UiPathでは、基本アクティビティの中に含まれる「OCRでテキストを取得(Uipath.Core.Activities.GetOCRText)」を使用することで、セレクターを使用してPDFファイルやWebサイト上の画像から数字・テキストを読み取ることができます。
公式パッケージの「Uipath.PDF.Activities」や「Uipath.IntelligentOCR.Activities」パッケージをインストールすることで、PDFファイルからの数字・テキスト読込はより確実化が可能ですが、「Uipath.IntelligentOCR.Activities」を使用したOCRの仕組みは煩雑なため、別の機会に解説いたします。
「OCRでテキストを取得」アクティビティの使用方法
今回はOCRの使用がメインなので詳しい解説は省略いたしますが、PDFの処理を繰り返し行う場合は「繰り返し(コレクションの各要素)(ForEach)」アクティビティと「アプリケーションを開く(OpenApplication)」アクティビティを使用し、PDFが格納されているフォルダーから繰り返してPDFファイルを開き、繰り返しの中に「OCRでテキストを取得」アクティビティを組み込む形でフローを作成すると良いでしょう。
因みに、UiPath StudioXを使用している場合は「繰り返し(フォルダー内の各ファイル)」アクティビティが存在しているバージョンもあるため、こちらを使用しても良いでしょう。
<数字・テキスト取得範囲の指定>
「OCRでテキストを取得」アクティビティは、前章で触れた通りセレクターを使用してテキストを取得したい範囲を指定可能です。Web上の画像から取得したい場合は、「要素の有無を確認」アクティビティや「テキストを取得」アクティビティのように画像を選択することが最適です。
PDFファイルの場合、文字列を選択出来る場合と出来ない場合があります。文字列が選択できない場合、ページ一枚すべてのテキストを取得する場合は問題ありませんが、特定の箇所(例えば請求書の中の金額や請求先)ごとに数字・テキストを取得したい場合は不便が生じます。
その際使用できるのが、セレクターの範囲指定です。
文字列が選択できる場合は、通常のセレクター取得と同様に選択するだけで指定完了です。
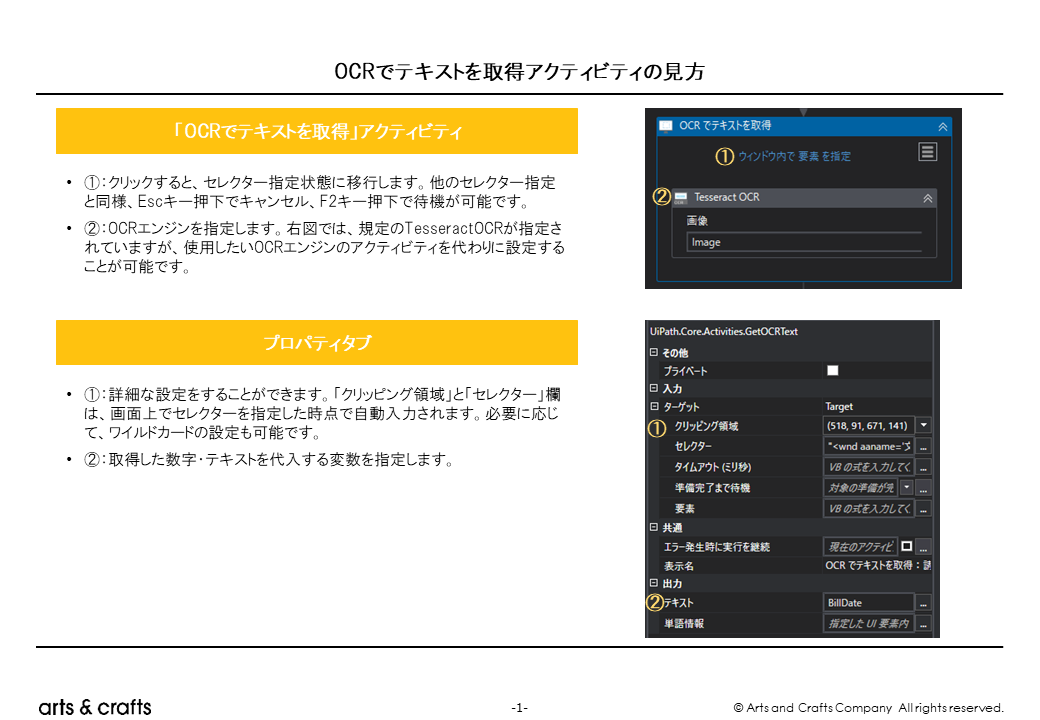
「OCRでテキストを取得」アクティビティは、取得したい数字・テキストの箇所を指定するだけで、プロパティタブで詳細な設定は不要です。必要に応じて、ファイル名や数字・テキストの一部を汎用的に使用できるよう、ワイルドカード(文字列の一部を「*」に置換)して、指定すると良いでしょう。
<使用するOCRエンジン>
UiPathでは元々複数のOCRエンジンを指定することができますが、エンジンによっては日本語の取得ができないエンジン、別途費用が発生するエンジンがあります。「OCRでテキストを取得」アクティビティは、初期設定で「TesseractOCR」エンジンが指定されていますが、日本語対応のために別途準備が必要となります。そのため今回は、煩雑な処理をなるべくせずにOCRを使用可能な方法として、「Microsoft OCR」エンジンを使用して解説いたします。
「Microsoft OCR」は、日本語対応かつAPIキーの発行や追加費用の発生なく使用できるOCRエンジンです。既存で指定されている「TesseractOCR」エンジンのアクティビティを削除し、「Microsoft OCR」エンジンのアクティビティを設定することで完了です。
OCRエンジンは、設定するだけでRobotの稼働はできます。ただし、必要に応じてプロパティタブでより正確な数字・テキストを取得できる設定が可能です。
「Microsoft OCR」エンジンでは、数字・テキストを取得するファイルの種類の設定、取得するテキストの言語設定が正確性を上げられる設定だと考えられます。ファイルがスキャンしたPDFファイルであれば、「プロファイル」欄を「scan」に、リモートデスクトップの画面であれば「Screen」に設定することで、読み取り精度の向上が可能です。
また、言語設定では日本語、英語といった指定を、「japanese」や「english」と英語表記にし、引用符で括って設定することで、OCR時にその言語で読み取ることが可能です。

「OCRでテキストを取得」アクティビティのデメリット
今回紹介した、セレクターの範囲指定を使用してOCRを使用する方法では、PDFファイルのレイアウトが少しでもずれてしまうと取得箇所が変わってしまい、正しい値が取得できなくなる可能性があります。不変のテキスト(例えば、請求書における「請求日」や「請求額」といった項目名)をアンカーとして指定できず、多少のレイアウト変更でも取得したい数字・テキストが取得できなくなるためです。
「OCRでテキストを取得」アクティビティを使用する場合は、自社規定フォーマットの請求書や注文書のPDFファイルのようにレイアウト変更が少なく安定して取得できるものや、確実にセレクターを取得できるWeb上の画像が望ましいでしょう。なお、クリックでセレクターを指定できるPDFファイルであれば、このデメリットはほとんど発生しません。
「OCRでテキストを取得」アクティビティのメリット
複数のパッケージインストールや、事前の設定が必要ない分、非常に簡単にOCRを使用することが出来ます。更に、「Uipath.Core.Activities」にのみ含まれるアクティビティを使用しているため、環境に左右されないというメリットも挙げられます。
Excelや業務システムから発行したPDFのように、読み取りやすいファイルであれば、煩雑な指定をしなくて良い分UiPath初心者の方でも取り扱いやすいフローを作成できます。
他OCRエンジンとの連携及びパッケージインストールについて
UiPathはABBYY社のOCRエンジンと連携が可能です。ABBYY系のOCRエンジンでは、より詳細なPDFファイルからの数字・テキスト取得設定が可能なため、ABBYYを既に使用している場合はこちらを使用するのが最も確実です。
他にも、OCR数に応じて費用が発生しますが、Google Cloud Vision OCRや、Azureアカウントがあれば使用できるMicrosoft Azure ComputerVision OCRといったエンジンが選択可能です。
UiPath上でPDFファイルにアンカーを設け、より正確なOCRでの数字・テキスト取得をする場合は、「UiPath.IntelligentOCR.Activities」および「UiPath.MachineLearningExtractor」をインストールし、設定する方法が挙げられます。この方法については、前述通り別途説明とさせていただきます。
UiPathでPDFファイルをより便利に扱う
近年、PDFファイルを使用した請求書や注文書のやり取りが増えているかと思います。それに伴い、UiPathで処理を自動化できるようになれば利便性が向上されるでしょう。OCRでの数字・テキスト取得方法は、今回の「OCRでテキストを取得」アクティビティだけではなく、Citrixの相対的スクレイピングを使用した取得方法もあります。前述の「Uipath.PDF.Activities」をインストールすることで、PDF内の画像を抽出したり、PDFを結合したりといったアクティビティが使用できるようになるため、今回の「OCRでテキストを取得」アクティビティと併せて使用し、より迅速かつ簡単にPDFファイルを扱うことが出来るようになるでしょう。
UiPathでは様々な方法でOCRを使用し、PDFファイルやWeb上の画像から数字・テキストを取得することが可能なので、使用意図に合わせてアクティビティを選ぶと良いのではないでしょうか。
【参考】
熊谷菜海
アーツアンドクラフツConsulting & Solution事業部/プログラマー。得意分野はRPA
